Perception-grounded Analytics for Vocal Expression
What expressive, paralingual elements do people hear in both expressive, unprompted speech and scripted speech? How do male and female vocal expression patterns compare? And what are the relationships among perceived prosody, voice quality, emotion, and conversational cues? Finally, what measurable acoustic correlates reflect these perceived expressive elements? This research explores these questions and produces software analytics which support detection of perceived elements of expression, described in the language which everyday listeners use to express what they hear. This approach serves application developers well, because application developers must produce interfaces which align with human perception and human description.
In contrast, most of the existing voice analytic techniques and software packages analyze the voice in terms of low-level features suitable for audio engineers, not everyday listeners. For example, common voice analysis features from audio engineering include “MFCC,” “jitter,” and “shimmer,” but not a single listener in our studies used these concepts to describe what they heard. Software analytics which are aligned with the human listener could, therefore, enable efficient development of many new software applications. Furthermore, the methods described in this research, if widely adopted, could potentially result in widespread production of application-suitable analytics for all modalities of human expression.
Papers and Presentations
Mary Pietrowicz, Mark Hasegawa-Johnson, and Karrie Karahalios, “Discovering Dimensions of Perceived Vocal Expression in Semi-Structured, Unscripted Oral History Accounts,” International Conference on Acoustics, Speech, and Signal Processing (ICASSP) 2017.
Mary Pietrowicz, Mark Hasegawa-Johnson, and Karrie Karahalios, “ Acoustic correlates for perceived effort levels in male and female acted voices,” J Acoust Soc am Aug;142(2) pp 792-811, 2017.
Mary Pietrowicz, Mark Hasegawa-Johnson, and Karrie Karahalios, “Male and Female Acoustic Correlates for Perceived Effort Levels in Acted Speech,” Midwest Speech and Language Days & Midwest Computational Linguistics Colloquium (MLSD & MCLC) 2016 (presentation).
Mary Pietrowicz, Mark Hasegawa-Johnson, and Karrie Karahalios, “Acoustic Correlates for Perceived Effort Levels in Expressive Speech,” INTERSPEECH 2015.
Crowdsourced Sound Composition
Music creation has long been the domain of trained composers. Many kinds of compositional styles and notation exist, and they reange from traditional notated composition on the musical staff, to completely electronic compositions which have no score, to popular music notated in lead sheet format, to electro-acoustic compositions (partially notated), to improvisational, and more. Yet, all styles require training and practice in order to produce coherent pieces. It is also a time-intensive and costly process for the composer. And, each individual composer has a personal style that defines the music they create. This is both enabling and limiting. It is enabling in that the composer has bounded the problem (he is a certain kind of composer, with certain skills, who uses certain techniques, and tends to write certain kinds of pieces, etc.), but limiting in that a single person will not explore the range of what is possible to create. In our project, we explore how non-experts can create sound compositions via crowdsourcing techniques, see how they explore the range of possibility, and observe how they go beyond the boundaries of individual capability.

Sound requestors use the CrowdBand interface to describe the kind of piece that they want to create. Our system breaks the problem down into three kinds of tasks (fundamental sound provisioning, sound assembly, and sound evaluation), creates a workflow, and automatically posts the tasks on mechanical turk.
Download foundation sounds that the crowd provided to create a composition about aliens, along with an example composition which uses them. And, download or play a short composition that the crowd created using the alien foundation sounds.
Papers
Mary Pietrowicz, Danish Chopra, Amin Sadeghi, Puneet Chandra, Brian Bailey, and Karrie Karahalios, “CrowdBand: An Automated Crowdsourcing Sound Composition System,” Human Computation and Crowdsourcing (HCOMP) 2013.
Behavioral and Visual Analytics
Sound and speech are ephemeral. We experience the sound in the moment, in the context of time, and often in community with others. Then, the sound is gone. Furthermore, the sound in human communication is multidimensional and includes the semantic meaning of words, the paralingual and prosodic expressive elements, the nonvocal gestures, and conversational cues. Automatic speech recognition work has explored the translation of the acoustic signal into text. The interpretation of the paralingual elements of speech, however, is frequently overlooked. This work explores the translation of the often overlooked expressive channels of human communication into a persistent, visual modality.
A sample “streams” visualization of the phrase “Hello World is shown below. Vertical position tracks pitch. Line thickness tracks sound amplitude, and color tracks sound class. Blue: obstruents. Pink: vowels. Aqua Green: sonorants.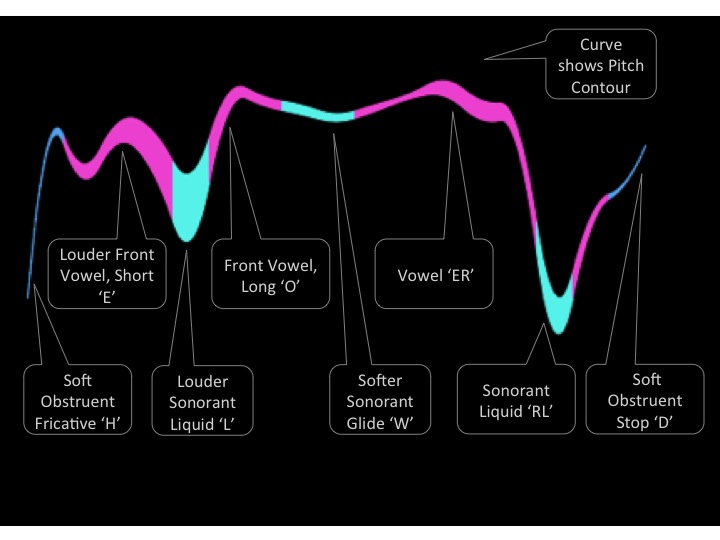
For comparison, a sample “particle” visualization of the same “Hello World” phrase is shown below. This visual form does not capture the continuity and phrasing of language, but it does a better job of reflecting emphasis and sonic timbre than the “streams” form of the visualization. 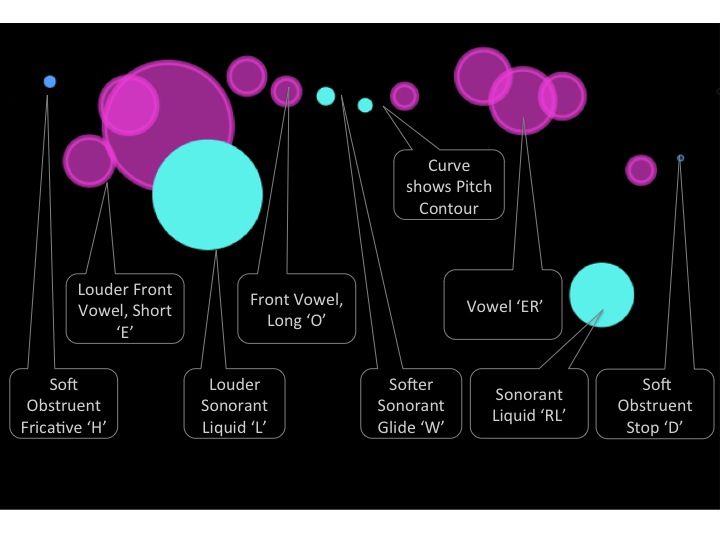 Capturing all of the expressive elements within a single visualization is likely not the best approach, given that prosody, voice quality, nonverbal quality, emotion, and conversational cues are, potentially, all of interest. Multiple views, selectable overlays, and/or customizable views will better serve the general case.
Capturing all of the expressive elements within a single visualization is likely not the best approach, given that prosody, voice quality, nonverbal quality, emotion, and conversational cues are, potentially, all of interest. Multiple views, selectable overlays, and/or customizable views will better serve the general case.
Discovering relationships among these various elements of vocal expression, and between other measurable biometric signals and behaviors is also of interest. The BEDA project (paper below) explored relationships between observable behavior in children, skin conductance measurements, and use of pressure vests(a common sensory integration therapy).
Papers, Presentations, and Workshops
Mary Pietrowicz and Karrie Karahalios, “Paralingual Analysis, Voice Visualization, and Mobile Devices as Enabling Technologies,” HCIC 2014.
Mary Pietrowicz and Karrie Karahalios, “Visualizing Vocal Expression,” CHIEA 2014.
Mary Pietrowicz and Karrie Karahalios, “Sonic Shapes: Visualizing Vocal Expression,” International Community for Auditory Display (ICAD) 2013.
Jennifer Kim, Melinda Snodgrass, Mary Pietrowicz, Karrie Karahalios, and Jim Halle, “BEDA: Visual analytics for behavioral and physiological data,” VAHC 2013.
Mary Pietrowicz and Karrie Karahalios, “Visualizing Vocal Expression,” for NSF Expeditions project: “Collaborative Research: Computational Behavioral Science: Modeling, Analysis, and Visualization of Social and Communicative Behavior,” 2013 (presentation).
Mary Pietrowicz and Karrie Karahalios, “Phonetic Shapes: An Interactive Sonic Guest Book,” CHIEA 2012.
Data Analytics & Sonification
How can we reveal time-dependent relationships and subtle differences within data sets, in creative and pleasing ways? Sonification, which leverages an inherently time-dependent, high-resolution, human sensory modality can help. It may be a particularly promising technique when integrated into human-in-the-loop analytic systems. This work demonstrates both the potential of sonification techniques in the analysis of complex data, and the potential for leveraging science data in the production of creative works.
Performances and Demonstrations
“Air Tropes,” A sonification of soybean growth data, which highlighted differences between CO2-enhanced and Ozone-enhanced environments for plant growth, and tracked growth patterns over time. This technique demonstrates the potential of sonification to reveal time and condition-dependent patterns in data. Part of the “Sounds of Science” collaboration between artists and scientists at the University of Illinois. Performed at the University of Illinois Krannert Art Museum, September 2014.
Interactive Art & Electroacoustic Sound Explorations
How can we extend common analytic techniques to follow a human within a space, and reflect relevant information about the surroundings in minimally-intrusive ways? Then, given that we can place humans in a space, how can we immerse them into an instrumented environment, using their natural human expressive capabilities, for the purposes of exploring multimodal human creativity? These projects emphasize the exploration of kinetic expression and gesture within immersive, interactive environments, and explore systems which enable the development of multimodal, interactive, immersive creative works.
Papers, Workshops, and Performances
“Kinetic Flame,” Interactive, 6-movement piece for dancer, percussion, motion sensors, electronics, lighting, and video. Performed at the University of Illinois Krannert Art Museum, April 2011. Available at: https://vimeo.com/23083695.
“Dark Star,” Interactive, algorithmic piece for dancer, motion sensors, and electronically-generated and modulated sound. The dancer’s movements modulated the sound and triggered complementary sonic events. Performed at the University of Illinois Krannert Art Museum, April 2011. Available at: https://vimeo.com/63711846.
Mary Pietrowicz, Robert E. McGrath, Guy Garnett, and John Toenjes,”Multimodal Gestural Interaction in Performance,” Whole Body Interfaces Workshop, CHI 2010.
“Remembering,” Composed piece for 4 voices and chamber orchestra, based on WWII oral history texts. Performed at University of Illinois, Smith Hall, October 2010.
“Voltage,” A 7-movement piece for flute, prepared piano, and electronics. Performed at Smith Hall, University of Illinois, July 2010.
Robert E. McGrath, Mary Pietrowicz, Ben Smith, and Guy Garnett, “Transforming Human Interaction with Virtual Worlds,” Workshop on Computational Creativity Support, CHI 2009.
John Toenjes, Thecla Schiphorst, and Mary Pietrowicz, Interactive Workshop on Laban Movement, 2009 (accelerometer-based, interactive motion analysis demonstration and presentation).
Guy Garnett, Robert E. McGrath, and Mary Pietrowicz, “mWorlds: Novel Human Interaction with Virtual Worlds,” Mardi Gras 2009: Virtual Worlds: New Realms for Culture, Creativity, Commerce, Computation, and Communication, 2009.
Developed the gesture tracking component for a remade version of “Astral Convertible,” an original Trisha Brown/John Cage piece. Dancers wore motion sensors embedded in their costumes, and the quality of their motion triggered lighting and sound changes. Performed at the Krannert Center for the Performing Arts, University of Illinois, February 2009. See this YouTube video for video clips and discussion about the project. Image below shows a still shot of the performance.

“Edream and Be Merry,” Interactive, improvised, geographically distributed performance for violin, flute, and distributed virtual worlds display. Developed portions of the interactive software, and performed the flute part. Performed at the Krannert Center for the Performing Arts, University of Illinois, HASTAC Blue Lights in the Basement event, April 2009. See a recording of this piece taken at the the National Center for Supercomputing Applications (NCSA) demonstration space.
Mary Pietrowicz and Polly Baker, “Location Aware Multimedia Delivery in an Art Museum,” I-Light Symposium Presentation, Indianapolis IN 2005 (presentation).
